Explore Versus Exploit
Explore vs Exploit Dilemma in Multi-Armed Bandits
What is the “Explore versus Exploit” dilemma about? What does it have to do with “Multi Armed Bandits”? Although these terms sound unappealingly technical, it is actually an intuitive framework to understand decision making. Let’s start by asking ourselves: Where should you have your next meal at?
Where do I eat at?
Deciding where to dine at has always been one of the biggest decisions (or at least mine) in our daily lives. Back at home, you have a good sense of which restaurants are best suited to your liking, and which to avoid at all costs. Your knowledge of the local restaurant landscape is largely complete, and relying on your prior experiences, you return to those restaurants that have provided an overall good dining experience repeatedly. Once in a while, when a new restaurant pops up, you can decide if you wish to explore it. If it turns out good, you can add it to your list of top 10 restaurants.

|
One of the most common decisions in life: To enter or not to enter?
Pic source: https://media1.fdncms.com/pique/imager/u/zoom/3095678/food_epicurious1-1.jpg |
Now imagine that you are on holiday (or if you are new to Vancouver like I am, this is probably a recent familiar situation) and you’re really hungry. The biggest decision you have to make now is: which restaurant are you going to eat at? Every restaurant is unfamiliar, and you have no inkling on which to patronise. Your stomach is grumbling and you decided to pick the nearest one called Restaurant A. Alas, the meal turns out tasting awful and the memory of this regretful dining experience is etched deeply in your mind. At your next meal, you avoid Restaurant A, and explore newer restaurants in the hope of a better culinary experience.
Does this sound familiar? You have just experienced the Explore vs Exploit dilemma.
A/B Testing
For a better understanding, we can also turn to a real world example that is heavily centered on the explore versus exploit dilemma: the A/B testing of different website pages. The term “A/B” may be a bit of a misnomer, as A/B testing can be performed on multiple webpages simultaneously. In commercial applications, the goal is to maximise the traffic or click through rates which would be the objective function. The A/B tests are done with the assumption of limited resources: each website page shown to a specific user is an opportunity cost at the expense of showing other pages.

|
A/B testing
Pic source: https://www.optimizely.com/optimization-glossary/ab-testing/ |
There are certain algorithms that are designed to decide which webpage to display to users. In the early part when there is maximum uncertainty about each webpages’ yield, the algorithms will tend to invest the resources to explore all webpages. When sufficient information is obtained about all webpages, the algorithm will emphasise on exploitation on webpages that show the best return on average.
Explore versus Exploit in Multi-Armed Bandits
The “explore versus exploit dilemma” is commonly found in use with another concept called “multi-armed bandits” (MABs). These “bandits” are essentially the webpages/restaurants, and each “interaction” with them provides a chance of obtaining a “reward”. Each round of reward (or failure to get it) provides information on the bandits, and this update is used for the next round of decision making. As the experiments progress, sequential decisions have to be made on allocating resources between:
- Exploring (if the value of information to be gained is high under high uncertainty)
- Exploiting (to secure gains by interacting with the best “bandit” based on current knowledge).
Ultimately, the end goal is to maximise accumulated rewards under limited resources.
For a clearer illustration, the following table illustrates the technical labels in the above mentioned analogy and example:
| Technical Term | Restaurant Choice | Webpage A/B Testing |
|---|---|---|
| Bandits | Restaurants | Webpages |
| Interaction | Dining at restaurant | Displaying webpage to user |
| Reward | If the meal was good | If the user clicks through |
| Resource Unit | Every meal | One web user’s traffic |
Uncertainty and its role in MABs optimisation
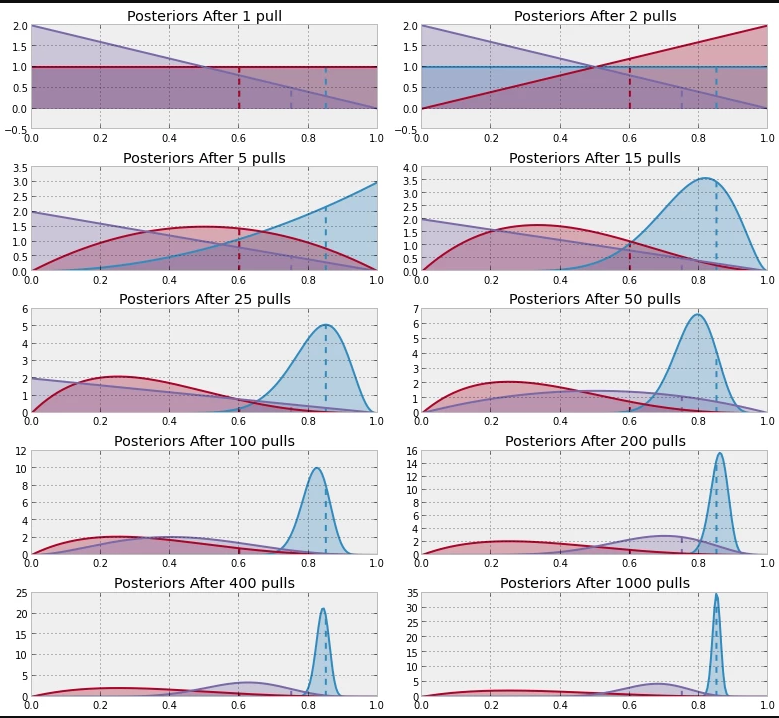
You may wonder how uncertainty is accounted for when it comes to real world examples such as in commercial A/B applications. The following picture showcases a simple MAB experiment with a specific algorithm. In this example taken from Data Origami 1, the simulation was done with 3 bandits of varying reward probabilities (0.6, 0.75, 0.85) and the true values are represented by the dotted vertical lines.
|
Progression of a multi-armed bandits experiment
Pic source: https://dataorigami.net/blogs/napkin-folding/79031811-multi-armed-bandits |
Each “pull” represents an interaction iteration and results in reward information. Although not shown, at the start of the whole experiment, we have no information about all 3 bandits. This uncertainty is represented by a uniform distribution for all 3 bandits. As more pulls are performed through exploration, we obtain information about individual bandits, which is used to update their probability distribution by reduction of variance (or width/spread).
After 1000 pulls, we can observe that the algorithm has fully transited into exploitation mode. Also worth noting is that the variance/spread of the varying bandits distributions are different at the end. Thus, during the progression, the algorithm decided that although it may have some level of uncertainty regarding certain bandits (particularly the 0.60 red coloured one), it knew enough that the poorer performing bandits were not worth allocating any further pulls. The bandit that was exploited the most consequently has the least variance and thus is represented by the thinnest distribution curve.
Algorithms
There are several algorithms available for MABs optimisation but I will briefly describe just two of them:
1. Random Selection
Random selection involves randomly choosing bandits for interaction. There is no consideration of past performance, which intuitively means that doing so will not optimally help attain the maximum cumulative gains, and there is no guarantee that we will converge onto the best performer in the long run.
2. Epsilon Greedy
Epsilon greedy involves setting aside a $\epsilon$ percentage of all interactions for exploration and $1-\epsilon$ for exploitation of the best known performer bandit. Given sufficient trials, we can eventually converge onto the best performer. However, the question is: can we get there faster?
Other algorithms that provide better performance than the above mentioned two (and definitely worth reading up on) include:
- Upper Confidence Bound (UCB)
- Thompson Sampling
Regret
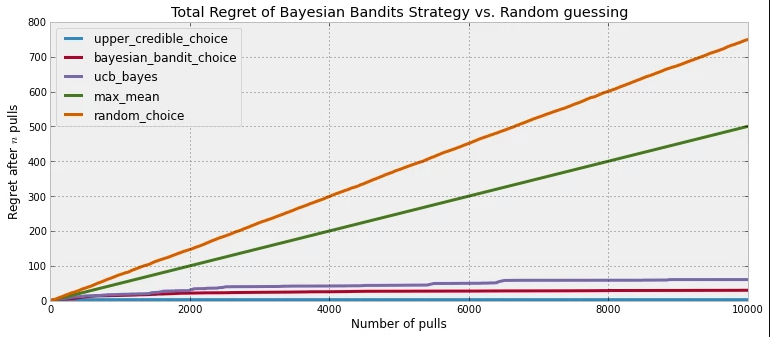
In tandem with the explicit goal of maximising accumulated gains in the long run, there is also the implicit concept of regret. Regret, or rather cumulative regret, represents the difference between the current rewards obtained from chosen actions versus the maximal rewards obtained if one had always chosen the best performer right from the start. Thus, the lower the cumulative regret, the better optimisation performance the algorithm will have. Using regret as a metric, one can assess the effectiveness of various algorithms as shown below2.
|
Cumulative regret comparison among various algorithms
Pic source: https://dataorigami.net/blogs/napkin-folding/79031811-multi-armed-bandits |
Assumptions
One key assumption about MABs is that the bandits reward functions are static or stationary for the period of experimentation. In the real world, this may not be the case. For example, certain webpages may be linked to topical objects like fashion clothing. Under such circumstances, the “reward return” will change with time and the results of your A/B testing may become obsolete. Consequently, one would have to constantly evaluate the validity of past results, and take action to create more “bandit” alternatives.
Another practical assumption about applying algorithms to the MABs problem for optimisation is that the reward system feedback needs to be quick. Unfortunately, not all A/B testing contexts meet that prerequisite. For example, clinical trials of drugs for diseases often involve prevention of death in patients. Some drugs may take a few months or years to show effect, but the inherent slow feedback loop prevents sequential evaluation by an algorithm.
Conclusion
I hope that this article has given you some brief insights on the intuition behind the explore versus exploit dilemma in the context of MABs. This draw similar parallels to our evaluative process of decision making in our daily lives as illustrated by the initial analogy. As this article draws to an end, I urge you to ponder about the next time you decide to try a restaurant and consider if you are “exploring” or “exploiting”.
If you are interested in finding out more or discussing this topic, please feel free to reach out to me as I am really passionate about it!
Further readings
In real world situations, we may not always start off with no information about all bandits. Going back to the analogy of picking a restaurant, we can obtain information from online reviews. This will formulate your prior knowledge, which in Bayesian terminology is termed priors. Using suitable priors can often lead you to more informed decision making, just as you may treat Yelp reviews of restaurants as reliable indication of good restaurants before trying them out. After you try the restaurant out, you update your prior knowledge with our own experience, which will help aid us in future meal decisions. This method of using data to update prior knowledge for inference is called Bayesian inference and you can always read more about it.
Citations:
